在我们日常的工作学习中,图片中的文件识别功能是非常常用的(如用户上传的图片做风控)。我们根据面向的对象不同,一般可以分成两类:
(1)面向普通用户;现有的图片文件识别工具有很多,常见有的微信截图工具中的自带的文字识别功能、专业OCR文字识别软件(如AI识别王、迅捷OCR识别软件);
(2)面向程序;在编码的过程中,需要实现自动识别图片中的文字功能,常见有供应商有阿里的OCR文字识别、百度的OCR文字识别等等,当然也可以自己使用搭建一套图片文字识别的服务。
下面我们将使用搭建一套自己的图片文字识别的服务平台。本平台中使用的技术有: + + + + 。
是一个开源的光学字符识别(OCR)引擎,是一个基于 OCR引擎的Java接口。
1、-OCR环境搭建
(1)基础依赖安装
放在上搭建的,以下是搭建的如下:
#1、基础依赖yum -y install gcc-c++ makeyum install -y autoconf automake libtool libjpeg libpng libtiff zlib libjpeg-devel libpng-devel libtiff-devel zlib-devel#2、下载pkg-configwget https://pkg-config.freedesktop.org/releases/pkg-config-0.29.tar.gz#解压tar -zxvf pkg-config-0.29.tar.gz#编译cd pkg-config-0.29/./configure --with-internal-glibmakemake checkmake install
完成基础依赖安装后可以看到
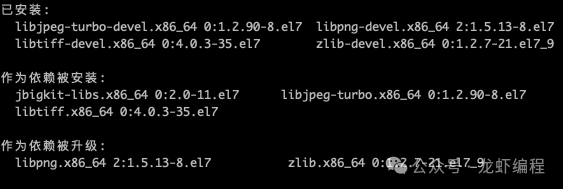
(2)上传的压缩包和相关的文件
依赖可以到官方网站下载(我这里下载好,直接可以使用,需要的软件的可以私信我)
上传文件到上
(3)安装
#1、解压文件tar -zxvf leptonica-1.79.0.tar.gz#2、编译./autogen.sh./configure --prefix=/usr/local/makemake install
编译完成之后的效果:
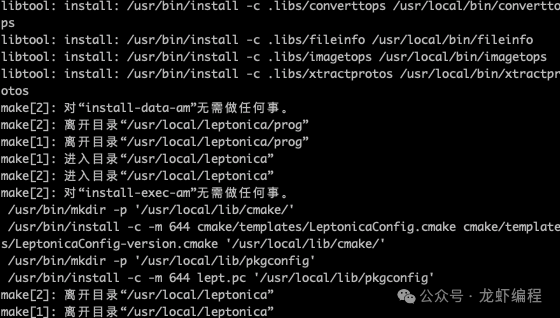
配置:
vi /etc/profile-----------------添加配置------------------------export LD_LIBRARY_PATH=$LD_LIBRARY_PAYT:/usr/local/libexport LIBLEPT_HEADERSDIR=/usr/local/includeexport PKG_CONFIG_PATH=/usr/local/lib/pkgconfig#刷新生效source /etc/profile
(4)安装
#1、解压文件tar -zxvf tesseract-1.1.tar.gz#2、编译./autogen.sh./configure --with-extra-includes=/usr/local/include --with-extra-libraries=/usr/local/includemakemake install
编译之后的效果:
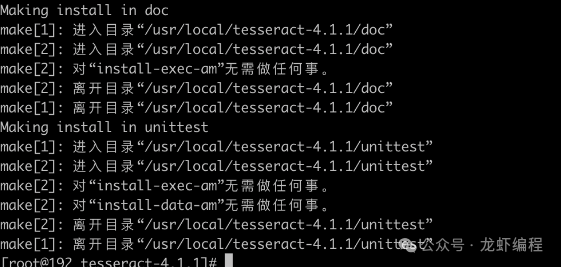
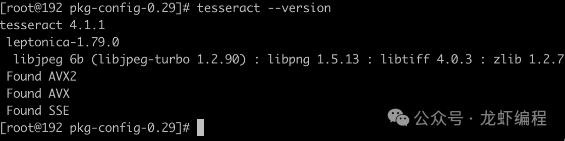
(5)测试安装是否成功
tesseract --version安装成功的效果:
(6)语言库放到-OCR指定的目录中

将这两个文件放在/usr///文件夹下
以上就完成了-OCR基础环境的搭建。在这个过程中可能出现如下的问题:
configure: error: Leptonica 1.74 or higher is required. Try to install libleptonica-dev package.问题的原因是没有安装pkg-。
2、搭建-OCR平台服务
(1)搭建基础的工程(不详细介绍)
(2)添加依赖
<dependency><groupId>net.sourceforge.tess4jgroupId><artifactId>tess4jartifactId><version>4.5.4version>dependency>
(3)配置yml文件
server:port: 8081#指定识别语言库的位置tess4j:datapath: /usr/local/share/tessdata
(4)配置
@Configurationpublic class TesseractOcrConfig {@Value("${tess4j.datapath}")private String dataPath;@Beanpublic Tesseract tesseract() {Tesseract tesseract = new Tesseract();//设置数据文件夹路径tesseract.setDatapath(dataPath);//设置为中文简体tesseract.setLanguage("chi_sim");return tesseract;}}
(5)编写识别的图片的服务
@Service@Slf4jpublic class OcrService {@Resourceprivate Tesseract tesseract;public String recognizeText(MultipartFile imageFile) throws IOException, TesseractException {// 转换InputStream sbs = new ByteArrayInputStream(imageFile.getBytes());BufferedImage bufferedImage = ImageIO.read(sbs);// 对图片进行文字识别return tesseract.doOCR(bufferedImage);}}
(6)编写识别的图片的服务
@RestController@RequestMapping("/api")@Slf4j@Api(description = "OCR服务")public class OcrController {@Resourceprivate OcrService ocrService;@PostMapping(value = "/recognize")public String recognizeImage(@RequestParam("file") MultipartFile file) throws TesseractException, IOException {// 调用OcrService中的方法进行文字识别String result = ocrService.recognizeText(file);log.info("识别图片的结果:{}", result);return result;}}
(7)本平台就不写页面了,直接使用展示效果,配置
#1、添加依赖io.springfox springfox-swagger2 2.7.0 io.springfox springfox-swagger-ui 2.7.0 #2、配置swagger@Configuration@EnableSwagger2public class SwaggerConfig {@Beanpublic Docket webApiConfig(){System.out.println("启动swagger");return new Docket(documentationType.SWAGGER_2).groupName("webApi").apiInfo(webApiInfo()).select()//接口中由/admin /error就不显示.paths(Predicates.not(PathSelectors.regex("/admin/.*"))).paths(Predicates.not(PathSelectors.regex("/error.*")))//扫描指定的包.apis(RequestHandlerSelectors.basePackage("com")).build();}private ApiInfo webApiInfo(){return new ApiInfoBuilder().title("OCR-API文档") //swagger页面上大标题.description("OCR微服务接口定义") //描述.version("1.0").contact(new Contact("java", "http://baidu.com", "1733150517@qq.com")).build();}}
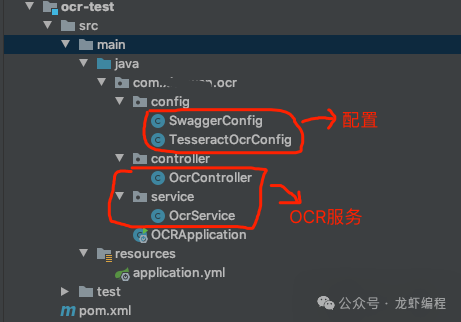
搭建完成之后的整体项目架构:
3、测试搭建的 OCR平台
(1)上传服务的jar包到了上
(2)启动项目(需要预先安装jdk和)
java -jar ocr-test-1.0-SNAPSHOT.jar启动成功的效果:

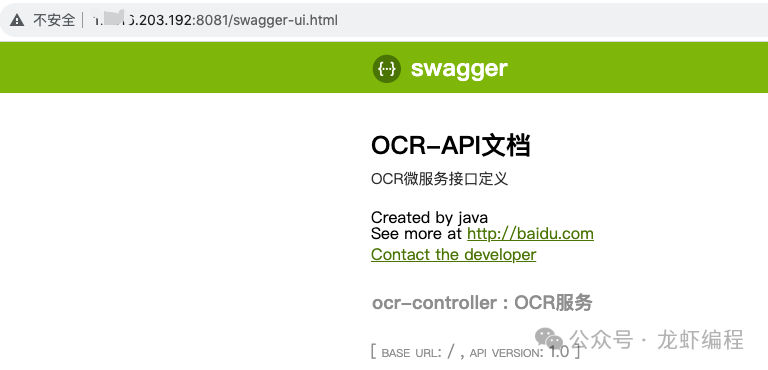
(3)启动(:port/-ui.html)
至此整个平台就搭建完成。
下面进行图片测试:
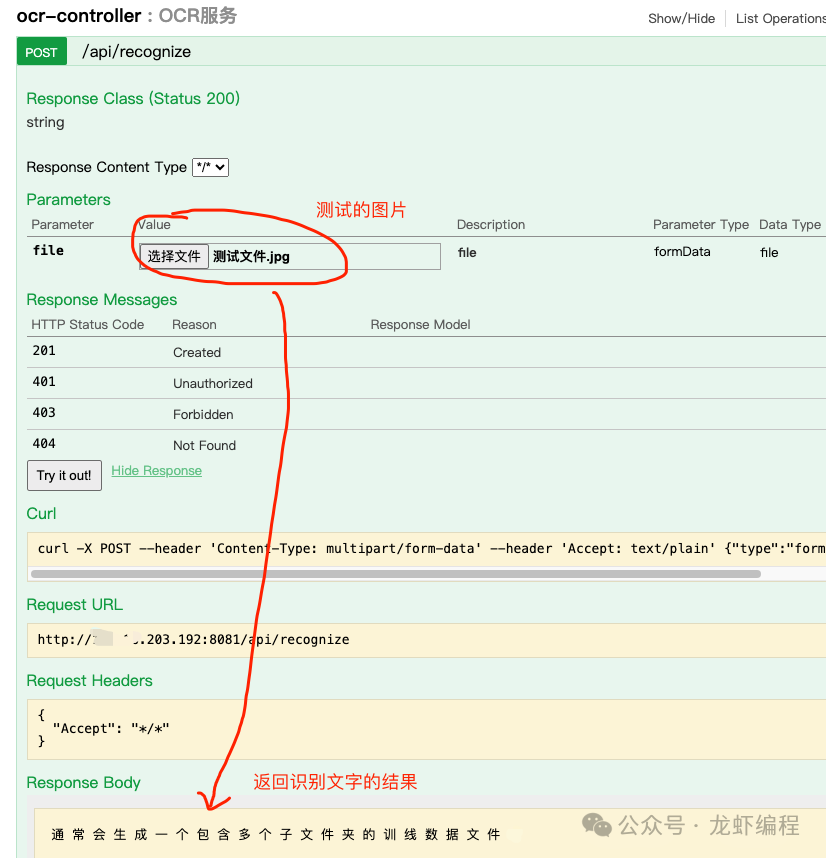
后端打印的日志:
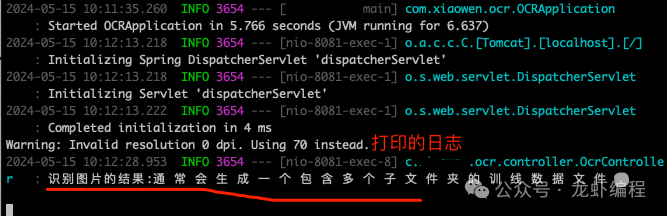
我们的图片文字识别的平台就搭建好了。



